朱诗生,王慧娟,李淳鑫
(汕头大学 计算机系,广东 汕头 515063)
随着国内工业发展迅速、吸烟人群年轻化,肺部疾病发病率每年呈上升趋势[1]。根据2019年国家癌症中心发布的全国癌症病情统计数据,肺癌的发病率和死亡率仍位居首位[2]。早发现、准确诊断以及正确治疗,可以让肺癌病人的死亡率降低。肺结节是肺癌早期的表现形式,准确地对肺结节进行分割可以提升医生对肺结节恶性度的判断水平,降低误诊率。为此,近年来许多研究人员专注于利用计算机辅助诊断系统实现肺结节分割的研究[3-5],提出了不同的分割理论和方法,如:形态学方法、阈值、聚类以及区域生长法等,但这些方法基本上都存在缺陷。Wu等人[6]在提取肺结节时采用了阈值法可用于提高灵敏度,但效率不高。Fischer B等人[7]对肺结节提取时使用了区域生长法,这种方法简单且效果挺好,但它需要医生事先勾画出种子点,不能实现自动检测,所以在临床上不太适用。Li等人[8]采用改进的随机游走算法对肺结节自动分割。潘子妍等人[9]提出一种基于多特征融合和XGBoost的肺结节检测模型。
随着机器学习和深度学习技术的快速发展以及广泛使用,国内外的许多研究人员在肺结节的分割研究中使用深度学习技术。Wang S等人[10]采用多尺度卷积神经网络算法来对肺结节进行检测和分割。Setio等人[11]提出了一种多视图卷积神经网络来对肺结节进行检测。Long等人[12]在卷积神经网络的基础上,提出了一种全卷积神经网络(Fully Convolutional Network,FCN),用卷积层替换卷积神经网络中的全连接层以获得图像中每个像素的分类结果,最终实现图像分割;
Ronneberger等人[13]提出了一种新的全卷积神经网络(U-Net)。苗光等人[14]为了提高肺结节检测的效率,提出了一种改进的U-Net模型,U-Net模型可以将网络高层和底层的信息相结合,比较适合用于处理一些复杂的医学图像,该网络模型在医学图像领域中的使用率较高。Xie等人[15]提出两个区域建立网络和一个反卷积层,改变Faster R-CNN的结构来检测候选结节,从而定位和提取肺结节。Chi等人[16]提出用扩展层取代卷积层,增加了感受域,提高网络学习图像全局信息的能力,对U-Net网络改进后构成DCNN(Deep Convolutional Neural Network)模型。
虽然目前已有较多肺结节检测的方法,但是,肺结节等医学图像具有特征复杂、目标区域小等特点,仅仅使用单个模型对其训练,仍存在分割精准度不高的问题,且还未达到临床应用的要求。因此,为了提高肺结节的分割精准度,该文提出了一种基于深度学习与模型集成的肺结节分割方法。该方法在数据采样上提出一种新的采样方法来处理类别不平衡问题,并通过在模型中连接条件随机场来进一步优化分割结果,最后对U-Net、LinkNet和SegNet这三个模型采用模型集成的方法,以提高肺结节分割的精准度。主要贡献有三个方面:
(1)提出了一种新的采样方法(随机方向采样法),可以有效缓解类别不平衡问题,避免模型对图像中肺结节位置的过度学习,并提高模型性能;
(2)提出在模型中加入全连接条件随机场对模型分割结果进行优化的方法,可以提高肺结节分割精准度;
(3)提出的模型集成方法,通过对多个模型分割结果的集成,可以进一步提高肺结节分割精准度。
该文主要使用了三种分割模型:U-Net、LinkNet和SegNet。这三种分割模型的结构相似,都是基于编码-解码结构,在编码部分都是由卷积层和池化层构成,解码部分则是进行上采样;
其主要区别是每个模型解码部分的上采样操作不同。U-Net为全卷积网络,由卷积层、最大池化层(下采样)、反卷积层(上采样)以及ReLU非线性激活函数组成,在U-Net模型中,上采样的操作是:对特征图进行反卷积,然后和高分辨率的特征图相加,即结合下采样各层信息和上采样的输入信息来还原细节信息。在LinkNet模型中,上采样的操作是:将每个编码器与解码器相连接,编码器的输入连接到对应解码器的输出上,在一定程度上可以减少处理时间,可以恢复降采样操作中丢失的信息,解码器可以共享从编码器的每一层学习到的参数,从而减少解码器的参数。SegNet模型,是一个对称网络,上采样操作是:使用最大池化的索引,依据编码中池化时的位置将特征图的值映射到新的特征图上,再在上池化层之后接一个反卷积层。
该文提出在分割模型中连接全连接条件随机场对模型分割结果进行优化。模型结构是由前后两部分组成,前一部分是分割模型结构,后一部分是全连接条件随机场结构。在前一部分,主要是用于特征提取,利用分割模型的结构特点,可以有效地结合深层(底层)和浅层(高层)信息,深层信息可以为类别识别提供依据,浅层信息可以为准确定位和分割提供依据。在后一部分,全连接条件随机场是一个概率图模型,可以利用它来考虑周围像素点的相关性,从而让分割的结果更加精准。
全连接条件随机场是对样本分布采取迭代拟合的方式,使原分布与样本分布之间的KL散度达到最小,从而优化分割结果。
条件随机场满足吉布斯分布:
(1)
其中,E(x|I)为能量函数,I为全局观测值;
能量函数为:
(2)
能量函数是由一元势函数和二元势函数组成;
其中一元势函数来自于前端模型的输出。二元势函数是用于描述像素点之间的关系,其计算公式如下:
(3)
其中,k(m)是一个高斯核,fi和fj表示i和j这两个像素点的特征向量,μ(xi,xj)是类别兼容性函数,w(m)是高斯核组合权重。该文使用的是两核势函数:
(4)
假设X的两个离散概率分布为P(x)和Q(x),则P对Q的相对熵为:
D(P‖Q)=∑(P(x)log(P(x)/Q(x)))
(5)
通过迭代优化KL散度,取得原分布的近似。
(6)
迭代过程为:
(1)初始化Q。
(7)
(2)更新节点分布。
(8)
(3)兼容性转换。
(9)
(4)更新Q。
(10)
(5)归一化Q。
(6)迭代(2)~(5),直至收敛。
原始胸部CT图像中除了包含肺部区域外,还含有其他的边界噪声。为了减少图像中边界噪声对肺结节分割实验结果的影响,先对原始图像进行肺实质分割是很有必要的。下面将描述在文中对CT切片图进行肺实质分割操作采用的方法和步骤:
(1)标准化数据:对图像中像素点的值进行归一化;
(2)使用K-Means聚类方法:在这一步先选取肺部附近的图像,然后使用K-Means方法将透明组织和不透明组织(肺)进行分离;
(3)对第2步中的图像进行形态学操作:先对上一步中的图像进行腐蚀操作,用于除去颗粒状杂质,然后使用膨胀操作(吞噬部分血管);
(4)筛选连通区域:对第3步中的图像进行连通区域标记,然后对其进行排序和筛选;
(5)膨胀操作:对上一步中的肺部mask图进行膨胀操作,填充一些空洞;
(6)得到最后的肺实质图像。
在对肺结节图像数据进行采样时,比较常用的方法是,先确定肺结节的位置,比如通过肺结节的轮廓计算出质心坐标,即代表肺结节在图像中的坐标位置,然后再以质心坐标为中心,截取一定尺寸的图像(比如32×32或者64×64),同时获得其相应的标签图,最后当成实验的数据集。这种方法操作比较简单方便,但是这种采样方法会让采样所得图像中肺结节的位置都是在图像的中心位置,在用于训练模型时,会出现模型对肺结节位置过度学习的现象,导致模型泛化性能低下。
针对上面提到的问题,该文提出了一种新的采样方法(随机方向采样法),它可以增加数据的多样性,提高模型的泛化性能。具体采样步骤为:首先,依据肺结节的轮廓坐标确定肺结节的正最小外接矩形,得到正外接矩形的左上角坐标(x,y)以及高(h)和宽(w);
然后,随机地对点(x,y)旋转某一角度,再依据其旋转方向对其进行采样。下面给出所提采样方法的坐标计算公式。
假设一个肺结节轮廓的正外接矩形左上角的坐标为(x,y),宽为w,高为h,坐标(x,y)可旋转的角度为θ,θ的可能取值为:
当坐标不旋转时,θ=0;
其中,ω可取任意整数。若ω=1,采样图像的尺寸为64×64,则该采样图像在原图中左上角和右下角的坐标分别为:(x,y-64+h)、(x+64,y+h)。
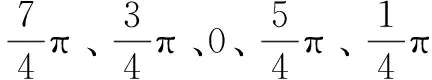
图1 随机方向采样示例图
为了进一步提高肺结节分割的精准度,提出了模型集成的方法。模型集成是将多个训练好的模型进行融合,基于某种方式来实现测试数据的多模型融合,使最终的结果能够“取长补短”,融合各个模型的学习能力,提高最终模型的泛化能力。
该文依据权重将三个模型的分割结果进行集成,得到一个更精准的分割结果,模型集成公式为:
result=w1×m1+w2×m2+w3×m3
(11)
其中,result为肺结节的最后分割结果,m1、m2、m3分别为三个模型的肺结节分割结果,w1、w2、w3分别为三个模型的权重,且w1+w2+w3=1;
模型权重的初始值为:w1=w2=w3,为得到更精准的分割结果,需要不断对权重进行更新迭代,当模型分割结果达到最优时,即分别得到三个模型的最优权重w1、w2、w3。
图2为模型集成的示例图,给出了模型集成方法的整个流程。

图2 模型集成示例图
实验所用的数据来源于LIDC-IDRI公开数据集,从数据集中挑选了920张含有肺结节的切片,然后将挑选出的切片数据划分成三个数据集:训练集、验证集和测试集。其中训练集包含736张切片,验证集和测试集分别包含92张切片。

图3 训练集数据示例图
在实验进行之前,需要对数据进行预处理。由于肺部CT图像中肺结节的尺寸较小,若直接将512*512尺寸的图像当成训练集数据,将会影响模型分割结果;
所以,先将肺结节图像裁剪成64*64的大小,再对图像进行归一化和去均值处理,然后用于模型训练。图3为训练集数据示例图。
在对肺结节的分割实验中,对不同模型的分割结果使用了一种评价指标─Dice系数。Dice系数,是一种相似度度量函数,可以很好地度量两个对象的相似度。下面给出它的计算公式:
(12)
其中,|X|与|Y|分别表示对象X与Y中包含元素的个数,|X∩Y|表示对象X与Y的交集。
实验环境是基于深度学习框架PyTorch结合Python编程语言搭建,操作系统为Windows10。在模型的训练过程中,使用Adam优化器进行优化,其中batch-size大小为16,模型初始学习率为0.01。
2.4.1 不同采样方法的分割结果比较
图4为U-Net模型使用不同采样方法在测试集上的分割结果。图4(a)为专家标注的肺结节图,图4(b)是使用传统采样方法的分割结果图,图4(c)是使用提出的随机方向采样方法的分割结果图。从图中可以知道,图4(b)中出现较多的假阳性结节,而图4(c)中由于使用了提出的新采样方法可以有效地避免模型对肺结节位置的过度学习,以提升模型性能,所以出现的假阳性结节较少。

图4 不同采样方式的分割结果
2.4.2 有无全连接条件随机场的分割结果比较
图5为U-Net模型是否有连接全连接条件随机场在测试集上的分割结果。图5(a)是专家标注的肺结节图,图5(b)是U-Net模型的分割结果图,图5(c)是在U-Net模型中有连接全连接条件随机场的分割结果图。从图中可以知道,图5(b)中的分割结果周边含有少量假阳性结节,而在图5(c)中,因为使用了全连接条件随机场来对分割结果进行优化,所以分割结果中假阳性结节更少。
表1给出了使用不同采样方法以及有无连接全连接条件随机场的模型在测试集上的分割结果。从表中可以看出,使用传统采样方法的分割结果明显低于新采样方法的分割结果,没有使用全连接条件随机场的分割结果也明显低于没有使用全连接条件随机场的分割结果,这是由于传统采样方法不能避免模型对肺结节位置的过度学习,全连接条件随机场可以通过结合肺结节周边像素点的信息来优化分割结果。所以可以得出,提出的新的采样方法(随机方向采样法)可以有效地提升模型性能;
采用的优化算法(全连接条件随机场),可以有效地优化分割结果。
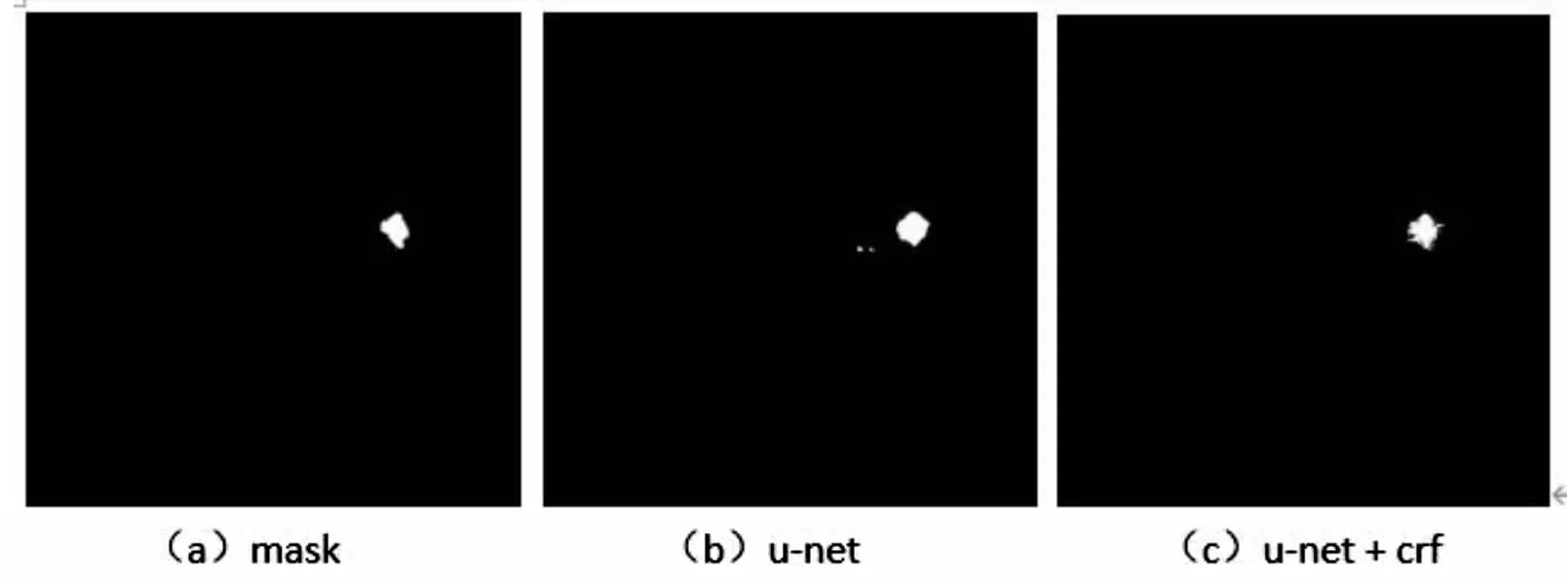
图5 有无全连接条件随机场的分割结果

表1 模型分割结果对比
2.4.3 不同模型的分割结果比较
图6为不同模型在测试集上的分割结果,这三种模型的训练集和验证集数据都是使用随机方向采样法采样的数据,且在模型后均有连接全连接条件随机场。图6(a)为U-Net模型分割的结果图,图6(b)为LinkNet模型的分割结果图, 图6(c)为SegNet模型的分割结果图,图6(d)为模型集成的分割结果图。

图6 不同模型的分割结果
由图6可以知道,提出的模型集成方法可以有效提高肺结节分割的精准度;
不同模型在训练中,主要学习的特征也不一致,而模型集成方法可以结合不同模型特点,集成不同模型的分割结果,来获得一个最优的分割结果。它们的Dice系数评估结果见表2。

表2 单个模型与模型集成分割结果对比
2.4.4 模型集成法与其他方法的分割结果对比
表3为模型集成方法在测试集上与其他方法的分割结果对比,从表中可以看出,提出的模型集成方法比Level Set[17]、Graph Cut[18]、Improved U-Net[19]以及FCN_32s有更好的分割性能。

表3 模型集成方法与其他方法的分割结果对比
为了进一步提高肺结节分割的精准度,提出了一种基于深度学习和模型集成的肺结节分割方法。该方法包括:在数据采样上使用提出的采样方法(随机方向采样法)来处理类别不平衡问题,避免模型对图像中肺结节位置的过度学习,以提高模型性能;
提出在模型后面连接全连接条件随机场以进一步优化分割结果;
最后利用提出的模型集成方法,对U-Net、SegNet和LinkNet这三个模型的分割结果进行集成,从而提高肺结节分割的精准度。在LIDC-IDRI肺结节公开数据库中实验验证表明,提出的肺结节分割算法可以提高肺结节分割的精准度。但是该算法也存在一些局限性,例如,在实验数据的选择上,只使用了公开数据集中的一部分数据;
在方法上,使用的是2D的分割模型,只关注了单张CT切片中的肺结节区域,忽略了相邻切片之间存在的信息。因此,算法还有待进一步完善。
扩展阅读文章
推荐阅读文章
恒微文秘网 https://www.sc-bjx.com Copyright © 2015-2024 . 恒微文秘网 版权所有
Powered by 恒微文秘网 © All Rights Reserved. 备案号:蜀ICP备15013507号-1